RNA-Seq Count数据的标准化(RPKM, FPKM, TPM)-学习笔记
测序得到的 read counts 数量会受到多种因素的影响,如 测序深度 和 基因长度 。除了上述两个主要因素外,还会有其他因素对read counts的检测有所影响,例如转录组的组成,GC含量,random hexamers引起的测序偏好等等。因此测序得到的read counts需要标准化后才能进行比较。标准化的方式有 RPKM , FPKM, TPM 。其中TPM被更多人认可。
RPKM: Reads per kilo base per million mapped reads (single-end sequencing)
FPKM: Fragments per kilo base per million mapped reads (paired-end sequencing)
RPKM与FPKM实际上一样的单位,只不过RPKM是在单端测序文库中使用,而FPKM是双端测序所用的。对基因长度(gene length)以及测序深度(mapped reads from library)都进行了校正。
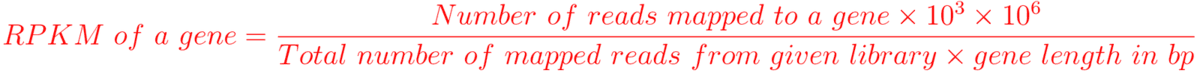
RPKM,FPKM
1 | #x为一个向量存储了每个基因的counts,而gene.length是相应于x中每个基因的长度的一个向量. |
TPM
TPM: Transcript per million

TPM对基因的长度进行了校正,计算比对到基因上的reads/基因长度得到长度校正的表达量 reads per kilobase (RPK)。再以文库中RPK之和作为Scale Factor求出TPM。
1 | TPM <- function(x, gene.length){ |
相比于RPKM使用文库大小(read counts之和)来作为文库校正因子,TPM使用RPK之和作为文库校正因子的好处是考虑了不同样本间的基因长度的分布。因为RPK是一个对基因长度进行校正后的表达量单位,所以RPK之和也不会再带入基因长度的bias。因此,如果需要比较的样本之间转录本分布不一致时(例如不同物种RNA-seq的比较),使用TPM是一个较佳的normalization方案。
RPKM和TPM这类方法就是为了使不同样本间的总体表达量趋于一致,让不同样本间的基因表达量有可比较性,而TPM能够更好地校正样本间的差异。
常用的Normalization 方法总结
| Normalization method | 描述 | 考虑因素 | 使用场景 |
|---|---|---|---|
| CPM (counts per million) | 使用read counts的总和校正counts | 测序深度 | 同一样本组重复样本之间的基因counts比较;不适用于样品内的比较或差异分析 |
| TPM (transcripts per kilobase million) | 每百万mapped reads中每kb转录本上的reads数 | 测序深度和基因长度 | 样本内或同一样本组样本之间的基因counts比较; 不适用于差异分析 |
| RPKM/FPKM (reads/fragments per kilobase of exon per million reads/fragments mapped) | 如TPM | 测序深度和基因长度 | 样本内基因间的counts比较; 不适用于样本间比较和差异分析 |
| DESeq2’s median of ratios [1] | counts除以样本特异的校正因子,该因子由基因计数相对于每个基因的几何平均值的中位数比率确定 | 测序深度及RNA组成 | 样本之间的基因counts比较以及差异分析; 不适用于样本内比较 |
| EdgeR’s trimmed mean of M values (TMM) [2] | 使用样本之间的加权截尾的对数表达量比值的均值进行TMM校正 | 测序深度,RNA组成以及基因长度 | 样品之间和样品内部的基因counts比较,适用于差异分析 |
在进行差异表达分析时,我们实际上并不会用到RPKM/FPKM, TPM,而是使用raw counts给到差异分析的工具。这是由于RPKM/FPKM和TPM都没有考虑到样本间文库组成的差异,因而不适合用于样本间差异分析。
获取基因长度
计算TPM或RPKM/FPKM等基因表达量时,除了基因的counts信息外,我们还需要知道基因的长度。由于可变剪接的存在,一个基因可能会有多个转录本,在进行基因水平的表达分析时,我们并不会区分各个转录本剪接变体的表达量,而是以基因为单位进行统计。目前,对于基因长度有多种定义,包括:
-
基因最长转录本;
-
多个转录本长度的平均值;
-
非重叠外显子长度之和:
-
非重叠CDS序列长度之和。
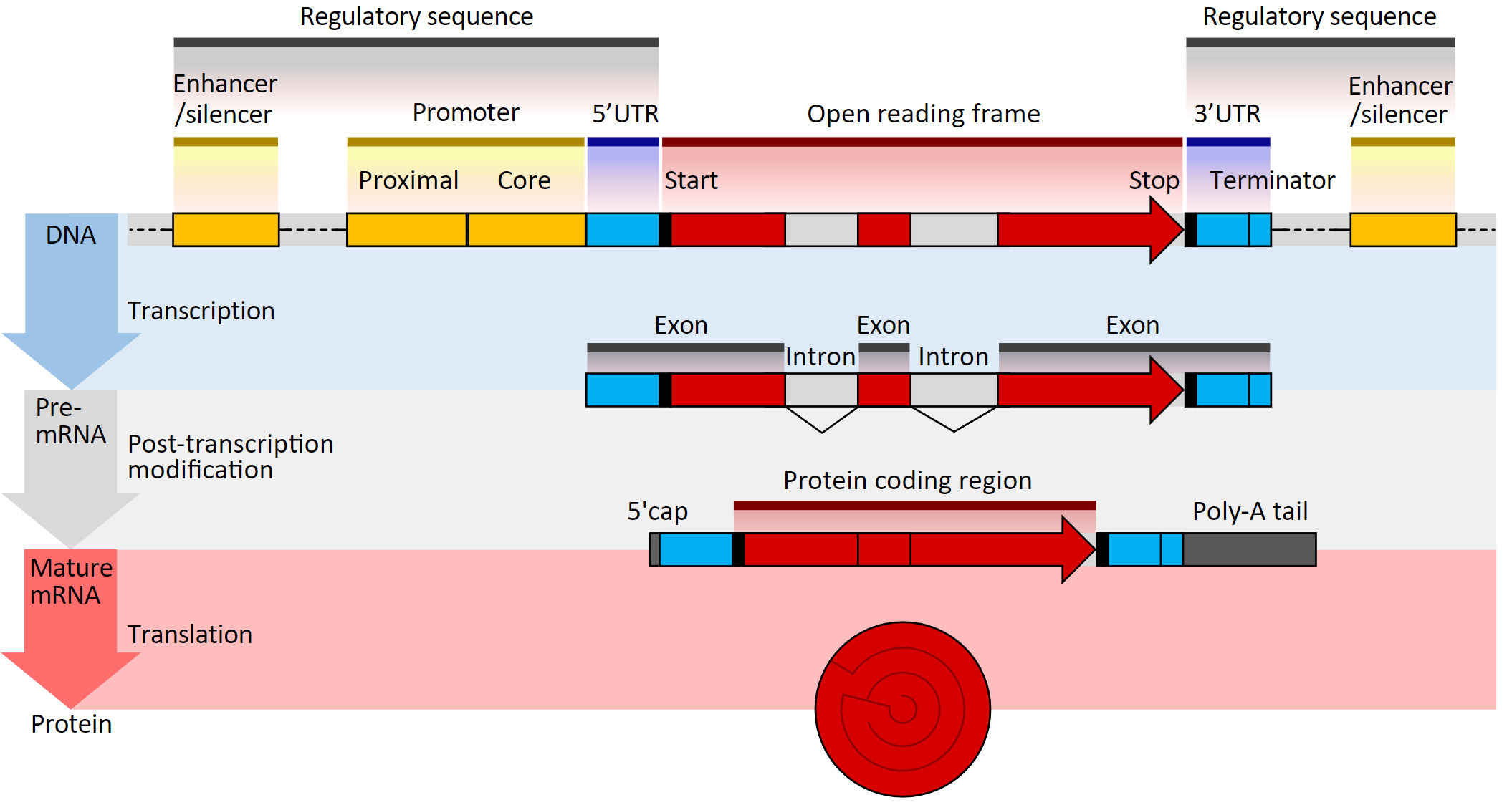
Figure Source: Gene structure
1 | #使用gtf文件在R中获取基因长度(非重叠外显子长度之和) |
GenomicFeatures还支持自己手动从指定数据库中构建TxDb对象,例如从 UCSC提取构建的makeTxDbFromUCSC()函数;从BioMart提取构建的makeTxDbFromBiomart()函数等方法可以用作替补方案(没有对应TXDB的R包时)。
tureCounts统计基因counts时,其输出的counts.txt文件中通常会包含一列长度信息Length。也是采用非重叠外显子作为基因长度。
参考:
-
理论-简述RPKM-FPKM-AND-TPM | Dean’s blog (thereallda.github.io)
-
R-获取基因长度 | Dean’s blog (thereallda.github.io)
-
[R]bioconductor之GenomicFeatures学习 - 简书 (jianshu.com)